
It is quite obvious that so-called deep learning is in fashion, especially in some fields of computer vision. In this post we would like to quantitatively evaluate whether this assertion is indeed true, and learn to do web scraping on the way.
Web Scraping consist in extracting useful information from websites by a computer program. In this post I’ll show a very basic example of web scraping written in Python in order to get the titles of the Computer Vision papers available in the open access repository of CVF. We will then count the number of title with deep-learning-related words in them.
Maybe web scraping is an overkill for this example, but it might come in handy for other applications.
First you’ll need to install these dependencies: lxml,
Python requests, and for more advanced examples Beautiful soup.
And here the code:
import requests
from lxml import html
conferences = ["CVPR2013","ICCV2013","CVPR2014","CVPR2015"]
for conf in conferences:
# Get the HTML text and find the classes of type 'ptitle'
response = requests.get("http://www.cv-foundation.org/openaccess/"+conf+".py")
tree = html.fromstring(response.text)
papers = tree.find_class('ptitle')
# Get all titles in a list
all_titles = []
for paper in papers:
title = paper.xpath('a/text()')
all_titles.append(title[0])
# Search for the 'deep'-inducing keywords
keywords = ['deep', 'cnn', 'convolutional', 'neural network']
count = 0
for title in all_titles:
for kword in keywords:
if title.lower().find(kword)>=0:
count = count+1
break
percent = count/float(len(all_titles))*100
print("%s: %.2f%%" % (conf, percent))As you can see, we scrape four of the last major vision conferences. From the respective websites, we get all titles (class ptitle), and then we count whether they have deep-learning-related words in them.
And here the results:
> python scraping_cvpr.py
CVPR2013: 0.85%
ICCV2013: 1.54%
CVPR2014: 3.70%
CVPR2015: 14.45%And the plot:
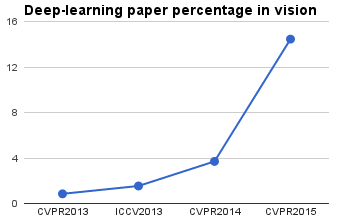
Quite impressive, right? So remember to put some of these words on the title of your next CVPR submission. :)