
Just after CVPR 2015, I described the exponential growth that deep learning had in vision paper (see the original blog post) by analyzing the paper titles.
Since the CVF just released the papers here, I updated the script and run it.
You can also find all papers in BibTex format in this folder.
Here the result in the command line:
> python scraping_cvpr.py
CVPR2013: 0.85% ( 4 out of 471)
ICCV2013: 1.54% ( 7 out of 455)
CVPR2014: 3.70% (20 out of 540)
CVPR2015: 14.45% (87 out of 602)
ICCV2015: 14.45% (76 out of 526)And the plot:
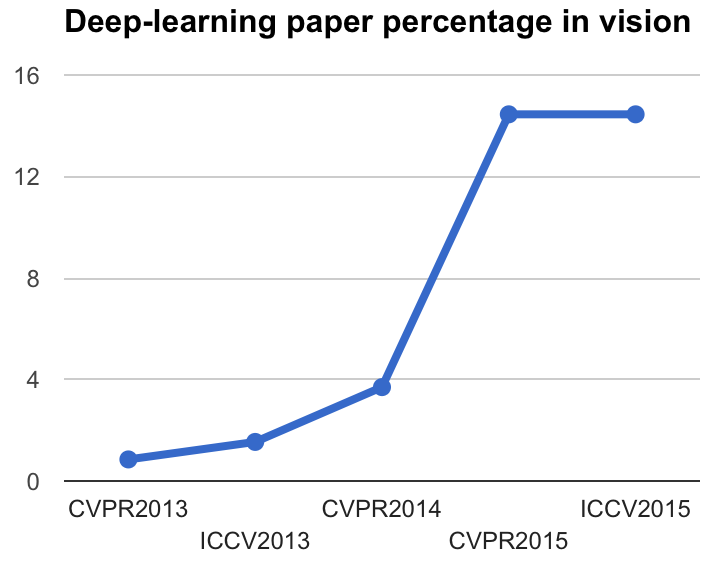
Surprisingly, the percentage of papers with some of the deep-learning keywords is the same for ICCV 2015 than for CVPR 2015. Does this mean that deep learning has plateaued in computer vision?
I feel that the general opinion will be that the field is still far from reaching a plateau. My interpretation for the titles not increasing is that deep learning is almost taken for granted in some sub-fields, so some authors do not feel the need to specify it in the title.
Here the updated code for you to try:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import requests
from lxml import html
conferences = ["CVPR2013","ICCV2013","CVPR2014","CVPR2015","ICCV2015"]
for conf in conferences:
# Get the HTML text and find the classes of type 'ptitle'
response = requests.get("http://www.cv-foundation.org/openaccess/"+conf+".py")
tree = html.fromstring(response.text)
papers = tree.find_class('ptitle')
# Get all titles in a list
all_titles = []
for paper in papers:
title = paper.xpath('a/text()')
all_titles.append(title[0])
# Search for the 'deep'-inducing keywords
keywords = ['deep', 'cnn', 'convolutional', 'neural network']
count = 0
for title in all_titles:
for kword in keywords:
if title.lower().find(kword)>=0:
count = count+1
break
percent = count/float(len(all_titles))*100
print("%s: %.2f%% (%d out of %d)" % (conf, percent, count, len(all_titles)))